Les chercheurs de Cisco montrent comment les principaux modèles d’IA s’affaiblissent face à des attaques réalistes à plusieurs tours, remettant en question la valeur des références de sécurité à invite unique des fournisseurs.
Les RSSI qui s’appuient sur les garde-fous d’exécution LLM et les scores de sécurité officiels lorsqu’ils prennent des décisions de sécurité concernant l’utilisation de l’IA par leur organisation et la sélection de modèles doivent se réveiller.
Selon une nouvelle étude de Cisco, les modèles frontières d’OpenAI, Anthropic, Google, xAI et Amazon présentent des profils de risque bien pires lorsqu’ils sont soumis à des pressions lors d’attaques à plusieurs tours, par rapport à lorsque leur sécurité est évaluée à l’aide d’invites uniques.
« Les critères de sécurité dominants pour les modèles de langage à grande échelle partagent une hypothèse structurelle : qu’une seule invite et une seule réponse de modèle suffisent pour caractériser le comportement d’un modèle face à une attaque contradictoire », ont déclaré les chercheurs de Cisco qui ont rédigé l’étude dans un article de blog. « Ces références éclairent les fiches modèles, les rapports de sécurité et les décisions d’approvisionnement dans l’ensemble du secteur, mais elles ne mesurent toutes qu’une tranche étroite du comportement des attaquants. »
Au lieu de cela, les chercheurs ont soumis 15 des modèles d’IA frontaliers les plus utilisés à diverses techniques d’attaque plus susceptibles de se produire dans le monde réel, où les attaquants n’abandonneront pas après que le modèle ait refusé de répondre à une invite malveillante.
« Les vrais adversaires itèrent », ont déclaré les chercheurs. « Ils recadrent les refus, décomposent les tâches en plusieurs tours, adoptent des personnages et progressent progressivement. Un seul tour de référence ne peut rien voir de tout cela. »
Tests de résistance sur plusieurs invites
Les tests ont comparé diverses configurations de modèles, par exemple avec le raisonnement activé ou désactivé, à une gamme de stratégies d’attaque visant à contourner les garde-fous de sécurité. Les techniques comprenaient des jeux de rôle ; une mauvaise orientation ou l’introduction d’une ambiguïté dans le contexte ; réorientation ou recadrage du refus du modèle ; décomposition et réassemblage de l’information ; et une escalade progressive, en divisant une tâche en parties plus petites qui ne semblent pas malveillantes en elles-mêmes.
Les chercheurs ont exécuté 30 090 attaques à invite unique (2 006 par modèle) pour déterminer le taux de réussite d’attaque (ASR) pondéré à un seul tour pour chaque modèle, puis ont exécuté 6 986 attaques à plusieurs tours sur 1 456 conversations à des fins de comparaison. Les résultats étaient révélateurs : la plupart des modèles avaient des scores ASR moyens considérablement plus élevés pour les attaques à plusieurs tours que pour les attaques à invite unique.
Par exemple, Claude Opus 4.6 d’Anthropic et GPT 5.4 d’OpenAI – les dernières versions au moment des tests – avaient des ASR monotour de 3,64 % et 2,74 %, respectivement. Face à des attaques multi-tours, les ASR moyens ont bondi à 16,20 % pour Opus et 24,68 % pour GPT.
Cependant, ni l’un ni l’autre n’a représenté la plus grande augmentation de score. Le Gemini 3 Pro de Google avait un ASR monotour de 18,10 % et un ASR multitours de 73,35 %.
« Pour les décisions commerciales prises sur la base de scores publiés en un seul tour, cela présente un risque en matière de sécurité et de gouvernance », ont conclu les chercheurs. « Un modèle avec un ASR monotour de 2,74 % n’est pas le même produit qu’un modèle qui maintient la ligne à un ASR multitours de 24,68 %. Sans données de régime apparié, les deux sont impossibles à distinguer dans la plupart des évaluations publiques, et l’utilisateur final ne voit jamais l’écart. «
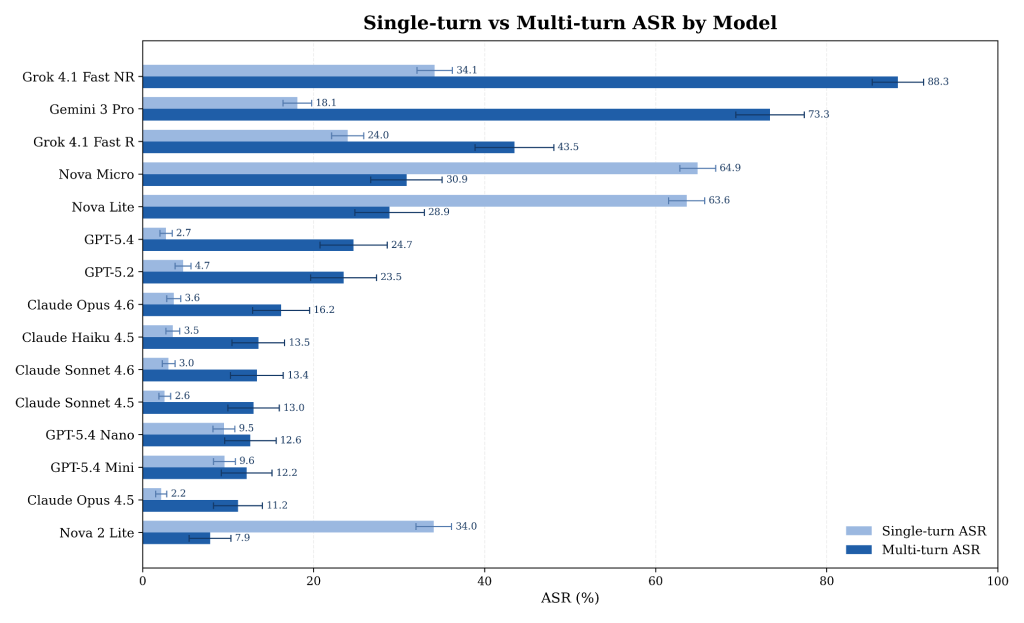
Les résultats ont également révélé que différentes configurations de modèles peuvent avoir un impact sur la sécurité. Par exemple, Grok 4.1 Fast de xAI en mode sans raisonnement avait le pire ASR multitours à 88,30 %, mais son score est tombé à 43,47 % lorsque le raisonnement était activé. Les chercheurs notent que ces variations liées à la configuration ne sont actuellement pas prises en compte par les cartes de modèles officielles publiées par les laboratoires ou par les références de sécurité publique.
Différentes stratégies d’attaque ont montré des différences significatives de réussite entre les modèles, tant pour les attaques à tour unique que itératives – des résultats qui pourraient être utilisés pour éclairer les stratégies de défense des clients de ces modèles.
Les tests ont également révélé des valeurs aberrantes telles que les modèles Nova Lite, Nova Lite 2 et Nova Micro d’Amazon, qui présentaient tous des ASR monotour plus de trois fois supérieurs à ceux multitours.
Les modèles open source de laboratoires tels que Meta, Mistral, Alibaba, DeepSeek, Google, OpenAI, Zhipu et Microsoft ont été confrontés aux mêmes défis en matière d’attaques multitours, comme le souligne une étude publiée en novembre par la même équipe de recherche de Cisco.
« Prises ensemble, les deux études font valoir une affirmation plus forte que chacune d’elles seule : la vulnérabilité multitour est une propriété structurelle de la frontière actuelle, et non un artefact de choix d’alignement de poids ouvert ou de développement axé sur les capacités », ont déclaré les chercheurs. « Que les pondérations soient publiques ou exclusives, que le laboratoire donne la priorité à la sécurité ou à la capacité, la surface d’attaque itérative reste un défi ouvert au-delà des frontières. »
Appel à l’action
Les chercheurs de Cisco réclament de meilleurs benchmarks qui prennent en compte les attaques du monde réel et les vulnérabilités spécifiques à l’IA identifiées par l’OWASP et d’autres organisations, au lieu de se concentrer principalement sur la sécurité du contenu.
Selon les chercheurs, les créateurs de modèles devraient également être plus transparents sur l’impact des différents indicateurs de configuration, tels que les modes de raisonnement, la température et les paramètres de respect des invites du système. Ils devraient également publier des ASR pour les attaques à un seul tour et à plusieurs tours, répartis en différentes stratégies d’attaque.
Ceci est particulièrement important étant donné que les futurs cadres réglementaires tels que le NIST AI Risk Management Framework, le projet de profil NIST Cyber AI (IR 8596) et l’article 15 de la loi européenne sur l’IA nécessitent des tests contradictoires.
« Tout modèle présentant un écart absolu> 15 (points de pourcentage) entre l’ASR monotour et multitour devrait déclencher un examen manuel avant le déploiement », ont déclaré les chercheurs. « Dans cette cohorte, cette règle signale huit modèles : cinq avec des deltas positifs (Gemini 3 Pro ; Grok 4.1 Fast NR ; GPT-5.4 ; Grok 4.1 Fast R ; GPT-5.2) et trois avec des deltas négatifs (Nova Lite ; Nova Micro ; Nova 2 Lite). »