

Votre automatisation Kubernetes pourrait jouer contre vous. Les contrôleurs malveillants créent des side-cars « fantômes » qui survivent aux redémarrages et se cachent à la vue de tous.
Au cours de mes années de sécurisation des environnements cloud natifs, j’ai remarqué un angle mort récurrent. Nous sommes obsédés par les « portes d’entrée » telles que les tableaux de bord exposés, les RBAC mal configurés ou les vulnérabilités des conteneurs non corrigées. Nous durcissons le périmètre, mais nous ignorons souvent les machines qui bourdonnent à l’intérieur.
Les adversaires sophistiqués sont allés au-delà des simples tactiques de frappe et de saisie. Ils ne veulent pas seulement faire fonctionner un mineur de crypto pendant quelques heures ; ils veulent de la persévérance. Ils veulent une base qui survit à un redémarrage de nœud, à un redémarrage de pod ou même à une mise à niveau de cluster.
Le mécanisme le plus dangereux et négligé pour cette persistance est le modèle de contrôleur Kubernetes. En compromettant ou en enregistrant un contrôleur malveillant, un attaquant retourne l’automatisation du cluster contre lui, créant ainsi une porte dérobée d’auto-réparation incroyablement difficile à détecter. C’est la technique ultime pour « vivre de la terre » à l’ère du cloud.
Armer la boucle de contrôle
À la base, Kubernetes est un moteur d’automatisation. Il compare constamment le (YAML) avec les (pods en cours d’exécution) et réconcilie la différence. Cette logique réside dans les contrôleurs.
Un contrôleur malveillant fonctionne en s’abonnant aux événements du cluster. Au lieu de déployer une application, il surveille des déclencheurs spécifiques, tels que la création d’un nouvel espace de noms ou le déploiement d’un secret spécifique, et injecte automatiquement du code malveillant.
Scénario : L’injecteur side-car « fantôme »
Nous avons vu cela se produire dans la nature avec Siloscape, une campagne de malware sophistiquée découverte par l’unité 42 de Palo Alto Networks. Contrairement aux scripts de cryptojacking classiques, Siloscape ne voulait pas seulement des ressources de calcul ; il voulait le cluster lui-même. Il ciblait les conteneurs Windows, s’échappait vers le nœud sous-jacent et utilisait les informations d’identification du nœud pour se propager via le serveur API.
De même, le groupe TeamTNT a été documenté en utilisant le malware Hildegard pour exploiter l’API kubelet à des fins de persistance. Ce ne sont pas des exercices théoriques en classe. Il s’agit de campagnes documentées au cours desquelles des attaquants ont utilisé le plan de contrôle comme une arme pour retourner Kubernetes contre ses propriétaires.
Prenons l’exemple d’un attaquant qui obtient un accès en écriture limité similaire au serveur API du cluster. Cet accès peut provenir d’informations d’identification de pipeline CI/CD compromises ou d’une fuite de kubeconfig d’un développeur qui dispose de suffisamment d’autorisations pour créer des MutatingWebhookConfigurations, mais pas des droits d’administrateur de cluster complets. L’attaquant n’a pas besoin de déployer directement une charge de travail ; il leur suffit de dire au serveur API d’exécuter leur logique sur les charges de travail.
Au lieu de lancer un pod bien visible nommé mining-rig, ils enregistrent un MutatingAdmissionWebhook.
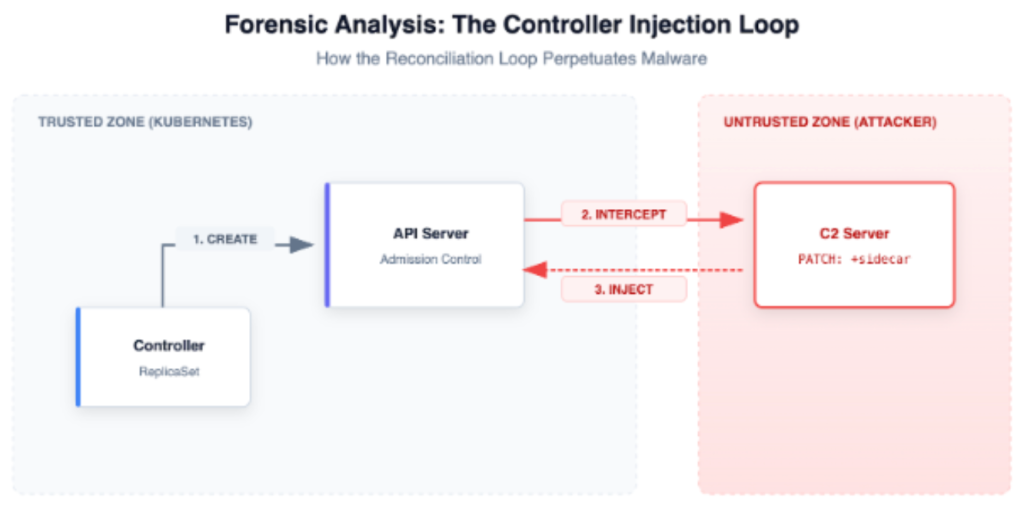
Comme l’illustre la figure 1, ce webhook fait office de contrôleur. Chaque fois qu’un pod légitime est créé (par exemple, un service de paiement), le serveur API envoie la définition du pod au webhook de l’attaquant pour approbation. Le webhook modifie la spécification du pod pour injecter un conteneur side-car malveillant avant qu’il ne soit conservé dans etcd.
Le danger caché :
- Il est invisible pour kubectl d’obtenir des pods : Le side-car malveillant est souvent caché au plus profond de la spécification du pod, et si l’attaquant utilise un nom commun comme proxy-agent, il se fond dans le trafic maillé légitime.
- Il survit au nettoyage : Si vous supprimez le pod compromis, le contrôleur de déploiement en crée un nouveau. Le nouveau déclenche à nouveau le webhook et la porte dérobée est réinjectée. La persistance est intégrée au cycle de vie du cluster lui-même.
Cartographie de la menace : Cette technique correspond à la persistance (TA0003) dans la matrice MITRE ATT&CK for Containers. Il exploite spécifiquement la propre boucle de contrôle du cluster pour maintenir l’accès, ce qui le rend beaucoup plus résilient que les portes dérobées traditionnelles basées sur un shell.
Chasser les fantômes dans l’API
Pour comprendre cela, vous devez regarder au-delà des journaux standard. Vous devez auditer la configuration du plan de contrôle du cluster.
1. Auditer les configurations MutatingWebhook
Exécutez cette commande pour voir qui intercepte vos créations de pod :
kubectl get mutatingwebhookconfigurationsRecherchez des webhooks pointant vers des URL ou des services externes dans des espaces de noms que vous ne reconnaissez pas (par exemple, kube-public ou default). Si vous voyez un webhook nommé Compliance-check pointant vers une adresse IP en dehors de votre VPC, traitez-le comme un signal d’alarme massif.
2. Surveiller les modifications de RoleBinding
Les contrôleurs ont besoin d’autorisations. Un contrôleur malveillant a besoin d’un ServiceAccount avec des privilèges élevés pour causer des dégâts. Surveillez vos journaux d’audit pour détecter les nouveaux RoleBindings qui accordent des autorisations de surveillance ou de liste sur les secrets ou les pods.
3. Recherchez les références de propriétaire anormales
Les objets Kubernetes utilisent OwnerReferences pour le garbage collection. Si vous voyez des pods prétendant appartenir à un contrôleur qui n’existe pas ou ne correspond pas aux modèles de déploiement standard, enquêtez immédiatement.
Verrouiller les machines
Pour empêcher la persistance basée sur le contrôleur, vous devez restreindre l’accès aux machines du cluster.
- Restreindre l’enregistrement du webhook : Utilisez Kubernetes RBAC pour garantir que seuls les administrateurs de cluster (et en particulier l’identité du pipeline CI/CD) peuvent créer ou modifier MutatingWebhookConfigurations. Les développeurs ne devraient jamais avoir cette autorisation.
- Stratégies réseau pour le plan de contrôle : Si vous exécutez des plans de contrôle autogérés, assurez-vous que le serveur API ne peut communiquer qu’avec des points de terminaison de webhook connus et inscrits sur la liste blanche.
- Signez vos images : Utilisez un contrôleur d’admission tel que Kyverno ou OPA Gatekeeper pour vérifier que l’image du conteneur dans un pod, y compris les side-cars injectés, est signée par la clé de confiance de votre organisation.
Réflexions finales
Les attaquants gravissent les échelons à mesure que les clusters Kubernetes arrivent à maturité. Ils ne se contentent plus de simples fuites de conteneurs ; ils ciblent la couche d’orchestration elle-même.
Le modèle Kubernetes Controller est puissant car il offre l’automatisation et l’auto-réparation. Entre les mains d’un attaquant, ces mêmes propriétés créent un point d’ancrage persistant et résilient. Nous devons arrêter de traiter le serveur API comme une boîte noire de confiance et commencer à auditer les webhooks qui collent nos clusters ensemble.
Cet article est publié dans le cadre du Foundry Expert Contributor Network.
Voulez-vous nous rejoindre ?


