

Connecter un LLM à vos données propriétaires via RAG représente une responsabilité énorme ; sans contrôles d’accès au niveau des documents, votre IA n’est qu’à une invite d’exfiltrer votre propriété intellectuelle.
Dans l’espace SaaS d’entreprise, les agents IA deviennent partie intégrante du produit SaaS. Pour rendre ces agents intelligents vraiment utiles, ils ont besoin de connaissances contextuelles spécifiques au client, ce qui manque intrinsèquement aux grands modèles de langage (LLM) standards, open source ou non, car ils ne sont pas formés sur les données propriétaires du client.
La génération de récupération augmentée (RAG) est le pont qui permet aux agents d’IA d’accéder en temps réel aux données les plus sensibles d’une entreprise : wikis internes, enregistrements CRM, référentiels de codes, système de suivi des tâches et propriété intellectuelle. Cependant, ce pont introduit d’importantes responsabilités en matière de sécurité. Le coût d’une mauvaise sécurité RAG dans un environnement SaaS est catastrophique, allant des fuites de données entre locataires et de l’exposition non autorisée de PII aux injections d’invites malveillantes.
Échecs de sécurité récents liés à RAG
Au cours de l’année écoulée, plusieurs incidents très médiatisés ont souligné les vulnérabilités des intégrations d’IA en entreprise :
- Exfiltration de données Zero-Click (fin 2025) : La vulnérabilité « EchoLeak » a démontré comment les attaquants pouvaient utiliser un e-mail spécialement conçu et non cliqué pour manipuler l’énorme pipeline RAG d’entreprise de Microsoft 365 Copilot. L’IA a été amenée à récupérer et à exfiltrer des données sensibles de l’entreprise sans aucune interaction des employés.
- Expositions aux bases de données vectorielles (2024 – 2025) : Plusieurs incidents impliquaient des clés API exposées pour les bases de données vectorielles. Lors d’une violation notable de la technologie financière, les attaquants ont eu recours à des « attaques de reconstruction » pour procéder à une rétro-ingénierie des intégrations dans des millions de portefeuilles d’investissement de clients d’origine. Un contournement similaire du contrôle d’accès à Pinecone a exposé plus de 200 000 dossiers de santé.
- Injection rapide indirecte dans les environnements de développement (août 2025) : Les attaquants ont implanté du texte caché et malveillant dans des fichiers publics GitHub README. Lorsque les développeurs utilisaient l’assistant IA de Cursor IDE pour résumer ces référentiels, l’IA exécutait involontairement les commandes cachées, accordant aux attaquants un accès non autorisé aux machines des développeurs.
- Empoisonnement de la base de connaissances (mars 2026) : Une opération massive a inondé les bases de connaissances externes de données manipulées. Étant donné que les systèmes de réponse IA s’appuient sur RAG pour des fonctionnalités à jour, cette « irrigation des données » a réussi à empoisonner les pipelines de récupération, obligeant les IA à transmettre de fausses informations et des publicités déguisées à des millions d’utilisateurs.
Pour sécuriser efficacement les pipelines RAG contre ces menaces évolutives, les organisations doivent bien comprendre leur architecture, cartographier les modèles de menaces et mettre en œuvre des stratégies de défense en profondeur.
Déconstruire l’architecture RAG de l’entreprise
Pour sécuriser un système RAG, vous devez d’abord comprendre comment les données y circulent. Un pipeline RAG d’entreprise typique fonctionne en trois phases distinctes :
- Ingestion et intégration (couche de données) : Les données brutes de l’entreprise sont extraites de sources telles que les ERP, les CRM et les référentiels de documents. Ces données sont nettoyées, découpées en segments plus petits et transmises à travers un modèle d’intégration qui convertit le texte en vecteurs numériques de grande dimension.
- Stockage et récupération (couche vectorielle) : Ces vecteurs, ainsi que les métadonnées (par exemple, balises source, autorisations d’accès), sont stockés dans une base de données de vecteurs spécialisée (comme Pinecone, Milvus ou ElasticSearch). Lorsqu’un utilisateur pose une question, le système exécute une recherche de similarité pour récupérer les morceaux de document les plus sémantiquement pertinents.
- Génération & orchestration (couche LLM) : Les données d’entreprise récupérées sont combinées avec la requête originale de l’utilisateur pour créer une invite augmentée. Le LLM utilise ensuite ce contexte pour générer une réponse très précise et fondée.
Voici une représentation visuelle de l’architecture RAG, superposée aux principaux vecteurs de menace ciblant chaque phase :
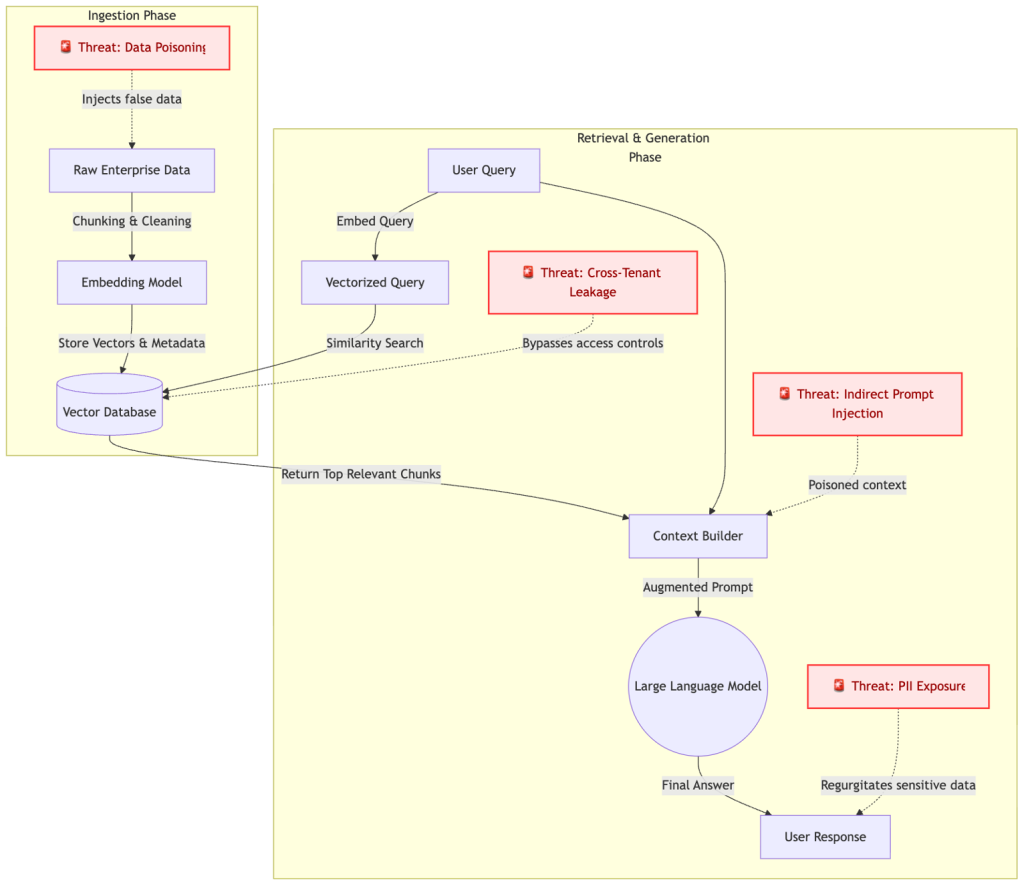
Le modèle de menace : comment les pipelines RAG sont attaqués
L’intégration de la récupération dynamique des données modifie fondamentalement le paysage des menaces liées à l’IA. Des frameworks comme l’OWASP Top 10 for LLM Applications mettent en évidence plusieurs vulnérabilités critiques spécifiques à RAG :
Injection rapide (directe et indirecte)
L’injection rapide reste la vulnérabilité la plus critique des systèmes d’IA. Alors que l’injection implique qu’un utilisateur tente de jailbreaker le chatbot, RAG introduit l’injection rapide indirecte. Ici, un attaquant cache des instructions malveillantes dans un document externe (par exemple, un ticket d’assistance client ou un PDF téléchargé). Lorsque le système RAG récupère ce document empoisonné comme contexte, le LLM exécute involontairement les commandes cachées. Cela peut conduire à une exfiltration de données ou au détournement des actions de l’agent IA.
Empoisonnement de la base de connaissances
Contrairement à l’injection rapide, qui cible la logique d’exécution, l’empoisonnement des données vise l’intégrité de la base de connaissances. Les attaquants injectent des informations manipulées, biaisées ou fausses dans les sources de données alimentant le pipeline d’ingestion. Étant donné que le LLM fait intrinsèquement confiance au contexte récupéré, il générera en toute confiance des réponses nuisibles ou factuellement incorrectes, détruisant ainsi la confiance dans l’application SaaS.
Divulgation d’informations sensibles et faiblesses des vecteurs
Les pipelines RAG traitent fréquemment des informations personnelles identifiables (PII) et une logique métier confidentielle. Si le pipeline ne dispose pas d’un filtrage robuste, les documents sensibles sont vectorisés sans limites d’accès appropriées. De plus, les vecteurs ne sont pas intrinsèquement sécurisés ; Des attaques sophistiquées d’« inversion d’intégration » peuvent procéder à une ingénierie inverse des vecteurs pour reconstruire le texte sensible d’origine.
Contamination entre locataires
Dans les environnements SaaS multi-locataires, une mauvaise isolation peut entraîner une contamination entre locataires. Un système de récupération mal architecturé pourrait permettre par inadvertance à un client de récupérer les données exclusives d’un autre client via une recherche sémantique parfaitement normale.
Prévention et détection
La sécurisation d’un pipeline RAG nécessite une posture de confiance zéro tout au long du cycle de vie des données. Vous ne pouvez pas compter uniquement sur le LLM pour vous comporter en toute sécurité ; la sécurité doit être superposée à l’ingestion, à la récupération et à la génération.
Stratégies de prévention
- Désinfectez le pipeline d’ingestion (DLP) : La prévention commence avant que les données n’atteignent la base de données vectorielles. Implémentez des contrôles de prévention contre la perte de données (DLP) pour analyser les documents, ils sont fragmentés et intégrés. Anonymisez, expurgez ou pseudonymisez les champs sensibles (comme les SSN ou les clés API) afin qu’une fuite, si elle se produit, produise des données inutiles.
- Conformité et confidentialité des données (le droit à l’oubli) : Enterprise SaaS est fortement soumis à des réglementations telles que GDPR, CCPA et HIPAA. Un défi majeur et souvent négligé dans les pipelines RAG est la suppression des données. Dans une base de données traditionnelle, la suppression d’un enregistrement utilisateur est une simple requête SQL. Dans une base de données vectorielles, si un utilisateur demande la suppression de ses données, vous devez vous assurer que chaque fragment vectoriel intégré et fragmenté lié à cet utilisateur est également détruit. Mettez en œuvre un balisage rigoureux des métadonnées lors de l’ingestion afin que les données clients spécifiques puissent être facilement localisées et purgées de la base de données vectorielle afin de maintenir une conformité totale.
- Cryptage de la base de données vectorielles : Traitez votre base de données vectorielles comme un actif hautement sensible. Assurez-vous que les données sont chiffrées au repos et en transit.
- Contrôle d’accès au moment de la récupération (RBAC et ABAC) : La défense la plus efficace contre les fuites de données consiste à appliquer les autorisations au niveau du document lors de la phase de récupération. Lorsqu’une recherche de similarité est exécutée, la base de données vectorielles doit strictement respecter les droits d’accès de l’utilisateur interrogeant. Si un utilisateur n’est pas autorisé à afficher un document dans le CRM sous-jacent, le système RAG ne devrait pas être en mesure de le récupérer à sa place.
- Isolation rapide et garde-corps d’entrée : Implémentez des garde-fous architecturaux qui séparent l’invite système du contexte récupéré et de l’entrée utilisateur. Pré-traitez les requêtes entrantes pour détecter les tentatives de jailbreak ou les signatures d’injection connues avant de les transmettre au LLM.
Stratégies de détection
- Filtrage de sortie : Ne faites pas implicitement confiance aux résultats du LLM. Déployez des filtres de sortie pour évaluer la réponse générée en cas de PII régurgités, de contenu toxique ou de comportement anormal avant de la transmettre à l’utilisateur.
- Télémétrie et veille sémantique : La journalisation standard ne suffit pas. Surveillez les pics d’utilisation des jetons (qui peuvent indiquer des attaques par déni de portefeuille) et suivez le taux de réussite/échec du composant de récupération. Recherchez les anomalies sémantiques, telles qu’un agent IA extrayant systématiquement des documents qui semblent sans rapport avec le rôle de l’utilisateur.
- Évaluez la dérive des données : Évaluez en permanence le pipeline à l’aide de frameworks tels que RAGAS pour détecter si la base de connaissances a été empoisonnée ou si la précision du modèle diminue avec le temps.
Opérationnaliser la sécurité avec les outils cloud de Google
La mise en œuvre de ces stratégies de défense en profondeur nécessite des outils robustes. Pour les organisations qui s’appuient sur Google Cloud, plusieurs services natifs d’entreprise sont directement liés au cycle de vie de sécurité RAG :
- Ingestion et désinfection des données : La protection des données sensibles du cloud de Google (anciennement Cloud DLP) inspecte, classe et supprime les données personnelles et financières sensibles des documents bruts avant qu’elles ne soient fragmentées et envoyées au modèle d’intégration.
- Stockage vectoriel et contrôle d’accès : La recherche vectorielle Vertex AI s’intègre directement à Google Cloud IAM, permettant aux développeurs d’appliquer des contrôles d’accès stricts au moment de la récupération et de garantir une forte isolation des locataires dans les environnements SaaS multi-locataires.
- Garde-corps d’entrée/sortie : L’armure du modèle Vertex AI sert de couche de sécurité dédiée entre l’utilisateur et le LLM. Il évalue les invites entrantes pour bloquer les jailbreaks et les injections d’invites indirectes et filtre les réponses sortantes pour éviter les fuites de données sensibles et le contenu toxique.
- Évaluation du pipeline : L’évaluation de Vertex AI évalue en permanence la qualité et la sécurité de votre pipeline RAG, en suivant des mesures critiques telles que « l’ancrage » pour garantir que les réponses de l’IA sont strictement basées sur le contexte récupéré et non sur des données hallucinées ou empoisonnées.
- Posture global de sécurité de l’IA : L’entreprise Security Command Center (SCC) intègre la gestion de la posture de sécurité de l’IA (AI-SPM) pour découvrir automatiquement les charges de travail d’IA dans votre environnement, identifier les erreurs de configuration (telles que les bases de données vectorielles exposées) et détecter les chemins potentiels d’exfiltration de données.
Conclusion
Alors que les agents IA assument des rôles de plus en plus autonomes au sein des plateformes Enterprise SaaS, les pipelines RAG constituent leur connexion vitale avec la réalité. Cependant, les avantages opérationnels de l’intelligence augmentée s’accompagnent de risques de sécurité importants. La sécurisation de ces pipelines nécessite une rupture avec les modèles de sécurité des applications existants.
En appliquant des contrôles d’accès stricts au point de récupération, en nettoyant de manière agressive les entrées et sorties et en maintenant une observabilité continue des opérations d’IA, les fournisseurs SaaS d’entreprise peuvent exploiter en toute confiance la puissance de l’IA tout en protégeant les actifs les plus précieux de leurs clients.
Cet article est publié dans le cadre du Foundry Expert Contributor Network.
Voulez-vous nous rejoindre ?


